以乳腺癌分类预测为例介绍机器学习中的逻辑回归。
逻辑回归(Logistic Regression)
参考:
Machine Learning小结(1):线性回归、逻辑回归和神经网络
机器学习之对数几率回归(Logistic Regression)
sklearn.datasets.load_breast_cancer
环境:
操作系统:Ubuntu 18.04
编程语言:Python 3.6.7
第三方库:numpy\matplotlib\scikit-learn
1 | |
定义
是一种用来解决分类问题的机器学习方法,用于估计某种事物的可能性。逻辑回归是一种广义线性回归,因此与线性回归分析有很多相同之处。他们的模型形式基本相同,都具有 wx + b ,其中w和b是待求参数。其区别在于他们的因变量不同,线性回归直接将 wx + b 作为因变量,即 h = wx + b ,而逻辑回归则通过逻辑函数将 wx + b 映射为一个非线性的特征p,表示某一分类的可能性,并将其作为因变量。逻辑回归的公式表示为:
\[h_\theta(x) = P(y = 1|x; \theta)\]即在给定自变量及其参数的情况下,y = 1的概率。
如果采用常函数作为逻辑函数,则该模型即为线性回归模型。在机器学习中,将这个逻辑函数称为激活函数。常用的激活函数有sigmoid、Tanh、ReLU、softmax等。
数据处理
采用sklearn乳腺癌数据集:
1 | |
乳腺癌数据集一共包括30个特征,target是诊断结果,即是否患有乳腺癌。将数据分为训练及和测试集,选择第1个特征和第27个特征作为自变量,target作为因变量。
1 | |
前向传播
调用matplotlib对所选数据进行绘图,所有 y = 0 的点将其表为绿色,y = 1 的点将其标为红色。
1 | |
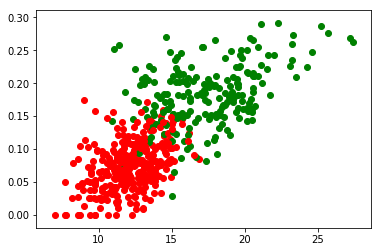
如果要对这组数据进行分类,就需要有一个这样的函数:值在0和1之间,当该函数大于某一个值时,判断其为1,小于时判断其为0。逻辑回归模型的假设是:
\[h(x) = g(\theta^Tx)\]其中,$\theta^Tx$表示其决策边界,即两类数据的分隔边界。g代表逻辑函数。对于二分类问题,这里使用一个常见的逻辑函数:Sigmoid Function,公式为:
\[g(z) = \frac{1}{1 + e^{-z}}\]python代码实现:
1 | |
该函数的图像为:
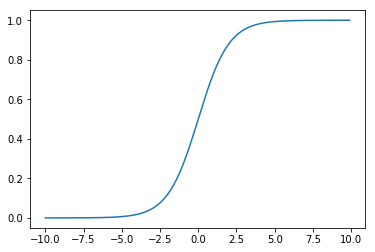
h(x) 的作用是,对于给定的输入变量,根据选择的参数计算 y = 1 的可能性。当 z > 0,g(z) > 0.5,预测 y = 1;当 z < 0,g(z) < 0.5,预测 y = 0。
由于我们采用了两个自变量x1和x2,所以逻辑函数为:
\[h(x) = g(\theta^Tx) = g(w^Tx + b) = g(w_1x_1 + w_2x_2 + b)\]为简化计算量,可以将x1x2和w1w2分别组合成矩阵,然后通过numpy进行运算。
\[z(x) = w^Tx + b = \left[ \begin{matrix} x_{11} & x_{21}\\ x_{12} & x_{22}\\ \vdots & \vdots\\ x_{1m} & x_{2m} \end{matrix} \right] = \left[ \begin{matrix} w_1\\ w_2\\ \end{matrix} \right] + b\] \[h(x) = g(\theta^Tx) = sigmoid(z)\]训练集共包含540个样本,将x1和x2合并成一个 (540, 2) 的矩阵,并使用随机数初始化参数w和b,然后计算h,并取m作为样本个数:
1 | |
反向传播
反向传播过程需要通过损失函数和代价函数来优化参数。对于线性回归模型,我们使用最小二乘法定义了损失函数。理论上来说,我们也可以用它定义逻辑回归模型的损失函数,但将sigmoid函数带入代价函数时,对w和J作图,将得到一个非凸函数。
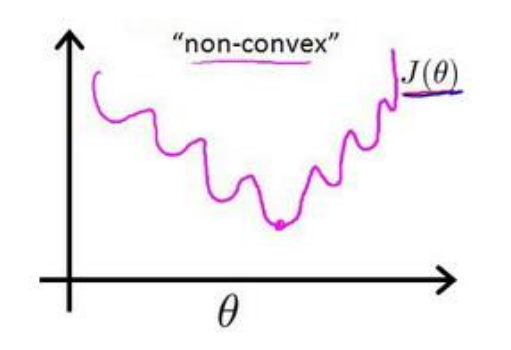
这意味着我们的代价函数有许多局部最小值,这将影响梯度下降算法寻找全局最小值。
线性回归的代价函数为:
\[J(\theta) = \frac{1}{2m}\sum\limits_{i = 1}^{m}[h_\theta(x^i), y^i]^2\]重新定义逻辑回归的代价函数:
\[J(\theta) = \frac{1}{m}\sum\limits_{i = 1}^{m}Loss(h_\theta(x^i), y^i)\]其中:
\[Loss(h_\theta(x^i), y^i) = \begin{cases} log(h_\theta(x)) & \text{if}\ y = 1 \\ log(1 - h_\theta(x)) & \text{if}\ y = 0 \end{cases}\]h与Loss( h(x), y ) 的关系如下图:
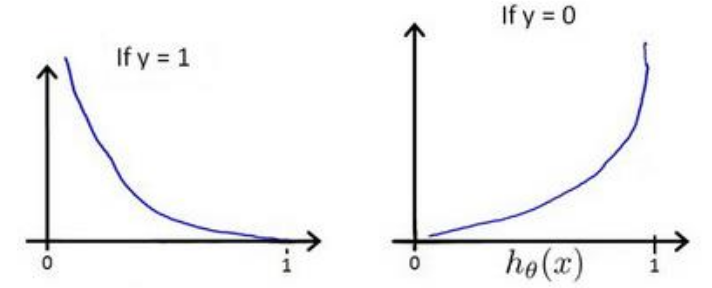
这样构建的 Loss( h(x), y ) 函数的特点是:当 y = 1且 h(x) = 1 时误差为零,且当 h(x) < 1 时Loss随h的减小而增大;当 y = 0 且 h(x) = 0 时误差为零,且当 h(x) > 1 时Loss随h增大而增大。
上式可以简化为:
\[Loss(h_\theta(x^i), y^i) = -y * log(h_\theta(x)) - (1 - y) * log(1 - h_\theta(x))\]即取 y 和 (1 - y) 表示两种情况,y = 1 时,(1 - y) 为0,y = 0 时,(1 - y) 为1。
python代码实现:
1 | |
得到代价函数以后,使用梯度下降算法来优化参数。算法为:
repeat until convergence {
\[\theta := \theta - \alpha\frac{\partial}{\partial \theta}{J(\theta)}\]}
求导后得:
repeat until convergence {
\[\theta := \theta - \alpha\frac{1}{m}\sum\limits_{i = 1}^{m}\{[h_\theta(x^i) - y^i]x^i\}\]}
推导过程:
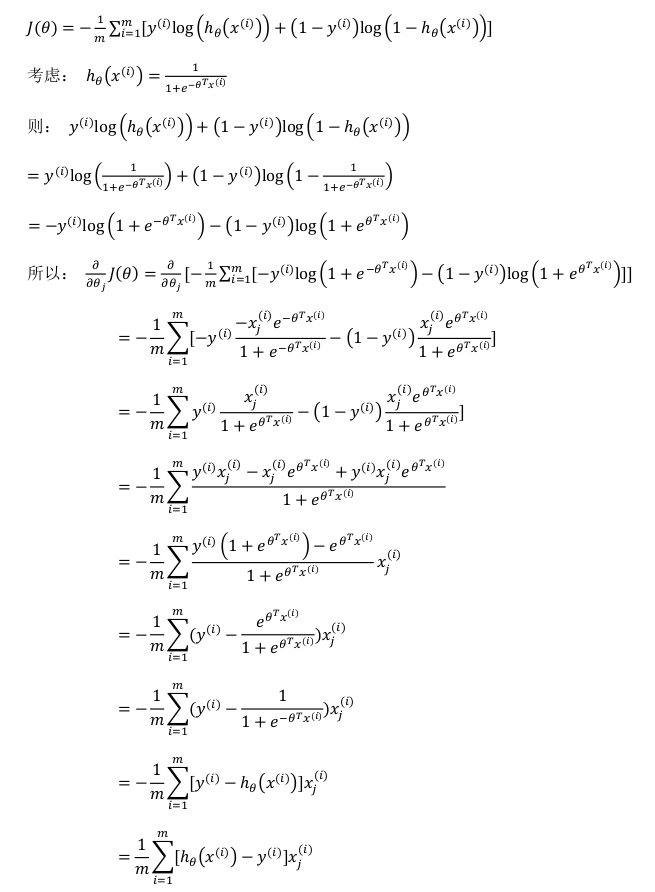
这个结果看起来是和线性回归梯度下降的结果是一样的,但由于其中假设的定义(h)发生了变化,所以逻辑回归的梯度下降跟线性回归的梯度下降完全不同。
逻辑回归的梯度下降过程为:
repeat until convergence {
\[w := w - \alpha\frac{1}{m}\sum\limits_{i = 1}^{m}\{[h(x^i) - y^i]x^i\}\] \[b := b - \alpha\frac{1}{m}\sum\limits_{i = 1}^{m}[h(x^i) - y^i]\]}
注意:先完成计算然后同步更新所有参数。
python代码为:
1 | |
使用matplotlib绘图:
1 | |
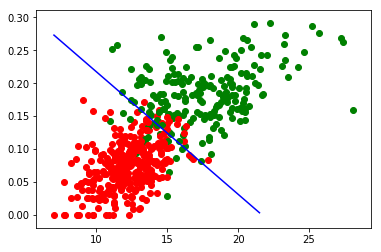
结果基本符合训练集数据。
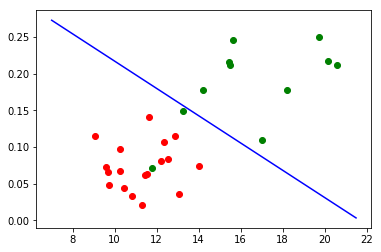
也基本符合测试集数据分布。